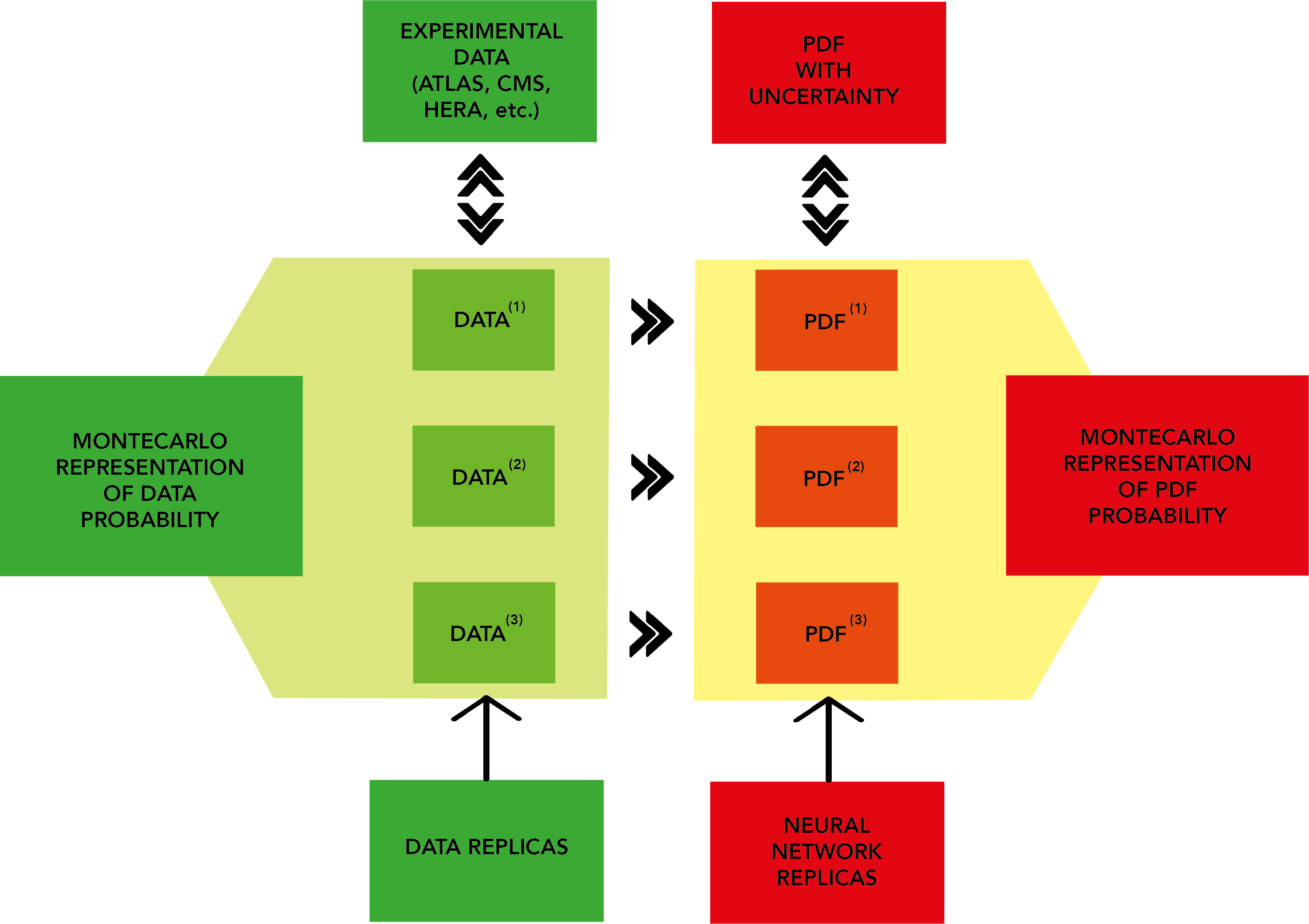
The figure above is a description of the NNPDF general strategy.
Experimental data is converted into an ensemble of N artificial Monte Carlo (MC) replicas or pseudodata. These are randomly generated in accordance with multi-Gaussian distributions centered around each data point, with variance given by the experimental uncertainty.
Each MC replica contains the same number of data points as the original experimental measurements. Given enough replicas, the MC set contains complete experimental information; the experimental central value can be retrieved by taking the mean and the experimental variance is simply the variance calculated over the different replicas.
NNPDF includes data from a number of experiments from fixed target colliders, (neutrino) deep inelastic scattering and Drell-Yan. These are in the form of observables such as cross sections, differential cross sections and structure formation.
Experimental data is converted from the raw format provided by individual experiments to a common format used in the t (known as commondata) by the code buildmaster.
Theoretical predictions are computed using external codes such as MCFM, DYNNLO, FEWZ and NLOjet++. The output from these is converted to higher orders as necessary using QCD and electroweak correction factors, and stored in grids. These values are then combined with DGLAP evolution kernels, which evolve PDFs from an initial reference energy scale to the energy scale of each experiment using the DGLAP equations. The output is stored in grids called APFELgrids.
Animation showing the training of PDFs are available: up valence, antiup and gluon; all pdfs